Overview WSL은 Windows Subsystem for Linux의 약어로 윈도우에 종속된 리눅스 시스템을 운영하는 것을 의미한다. 과거에는 하이퍼바이저(VMware, Virtualbox)와 같은 가상머신 소프트웨어를 설치하고 리눅스 시스템을 올려 사용했지만, WSL이 나온 이후로 윈도우 환경에서 편리하게 리눅스를 사용할 수 있다. WSL을 기본적으로 설치하면 WSL 1 버전이 설치되기에 이 포스트에서 WSL 2 설치 하는 방법에 대해 소개한다. Version Check 우선 WSL 버전을 확인한다. WSL 버전은 1과 2로 구분되는데 버전 1은 systemd를 파이썬 스크립트로 편법적으로 사용해야 이용할 수 있어 운영상 안전성이 상당히 떨어진다. 반면 버전 2는 공식적으로 systemd를 지원..
일전에 vscode를 구축하는 포스트를 발행한 적이 있다. 이 방식은 vscode 서버부터 NginX까지 구축을 진행하여 완전한 섯버 형태로 구축하는 내용을 다룬다. [Information Technology/Programming] - Code Server - 구축편 이 방식보다 더욱 편리하게 Code Server를 구축하는 방식이 vscode CLI server를 구축하는 것이다. 아마도, vscode 개발 팀에서 이야기하는 vscode의 발전 방향에서 지난 구축 방식은 Remote - SSH, Tunnels에 해당하고, 이번 포스팅은 Remote - SSH, Tunnels + Dev Containers 방식에 해당하는 것으로 추측한다. Prepare 우분투 리눅스 시스템(WSL도 가능) Install..
간단한 서버를 운영하기에 클라우드가 매우 편하다. 전세계에 다양한 클라우드 서비스가 있는데 가장 오래되고 높은 점유율을 가지고 있는 AWS를 이용한다. 클라우드 컴퓨터를 EC2라고 부르는데, 언제 어디서나 컴퓨터 디바이스 의존도가 필요없는 IDE 서버를 구축하기 위해 EC2 생성을 진행한다. Prepare AWS 계정 및 로그인 Setting Choose Region EC2를 본격적으로 생성하기 앞서 리전(Region)을 먼저 선택한다. 리전이 가지는 의미는 AWS 서비스의 국가적 위치를 의미한다. 모든 설정은 리전에 종속되기 때문에 본인이 구성한 AWS 환경이 보이지 않는다면 리전을 변경해 보는 것이 좋다. 코딩으로 AWS를 제어할 것이라면 주요 리전의 코드 네임인 ap-northeast-2를 기억해 ..
Cloudflare를 이용하여 도메인을 관리할 때 별도의 서브도메인 설정이 없는 경우 www 서브 도메인으로 트래픽을 전달하는 구성 방법을 소개한다. Purpose 흔히 웹 사이트에 방문할 때 www.google.com이나 www.naver.com 같은 도메인을 봤을 것이다. 주로 메인 웹 사이트에 www 서브도메인을 할당하는데, 이 구성은 google.com이나 naver.com을 방문해도 www 서브도메인이 자동으로 할당된다. Cloudflare를 이용해 도메인을 관리하고 있다면, 다음과 같이 설정하여 이 구성을 이용할 수 있다. Prepare Cloudflare 계정 Cloudflare에서 도메인을 구매했거나, 가지고 있는 도메인을 Cloudflare로 이관한 경우 Setting Set of Dom..
목차 Amazon Macie (1/2) - 구축편 Amazon Macie (2/2) - 활용편 소개 Amazon Macie는 Amazon S4 버킷에서 데이터를 검색할 때 사용하는 기능이다. 이를 특정 문자나 정규표현식을 사용하여 찾는다. 설명에는 기계학습을 사용하여 개인정보(PII)나 민감한 데이터를 식별할 수 있다고 소개한다. 구축 처음 Macie에 들어가면 기능 활성화를 진행할 수 있다. 첫 활성화 땐 30일 무료 평가판으로 자동 등록되어 무료로 사용할 수 있다. 최초 활성화를 하면 목적에 맞게 현재의 권한으로 접근할 수 있는 S3 버킷의 상태를 살펴볼 수 있다. 제일 먼저 설정해야 할 부분은 검색 결과이다. 민감한 데이터를 검색하고 찾아낸 결과를 새로운 S3 버킷에 저장한다. 본 포스트에서는 테스..
목차 Amazon Macie (1/2) - 구축편 Amazon Macie (2/2) - 활용편 소개 Amazon Macie는 Amazon S4 버킷에서 데이터를 검색할 때 사용하는 기능이다. 이를 특정 문자나 정규표현식을 사용하여 찾는다. 설명에는 기계학습을 사용하여 개인정보(PII)나 민감한 데이터를 식별할 수 있다고 소개한다. 활용 이제 Macie를 이용해 검색하기 위해 패턴을 생성한다. 패턴은 우측 패널에 설정에서 사용자 지정 데이터 식별자를 선택한다. 민감한 데이터인 폰 번호를 검색하는 정규표현식을 간단히 작성한다. 단순 문자열도 최대 50개까지 지정할 수 있고, 예외처리도 10개 까지 가능하다. 이제 검색은 검색 대상이 되는 S3 버킷을 선택한다. 버킷 선택은 우측 패널의 S3 버킷에서 선택 가..
페이지 목차 Code Server - 구축편 컨텐츠 목차 소개 구축 code-server 구축 및 설정 code-server 구축 code-server 운영 옵션 code-server 시스템 서비스 설정 NginX 구축 및 설정 NginX 구축 NginX의 패스워드 인증 구성 NginX와 Certbot을 이용한 https 통신 설정 참고 소개 대 클라우드 시대가 시작되면서 IDE를 로컬에 설치할 필요 없이 서버에 IDE를 구축하고 언제 어디서든 브라우저로 코딩을 할 수 있는 시대가 왔다. 이러한 환경은 개발자가 자신이 개발한 코드를 Github에 Push하고 다른 개발자가 Pull하여 받은 다음 개발하고, 충돌 문제를 해결하는 등의 환경을 실시간 동시 개발을 진행하도록 도와주어 더욱 편리한 개발을 할 수..
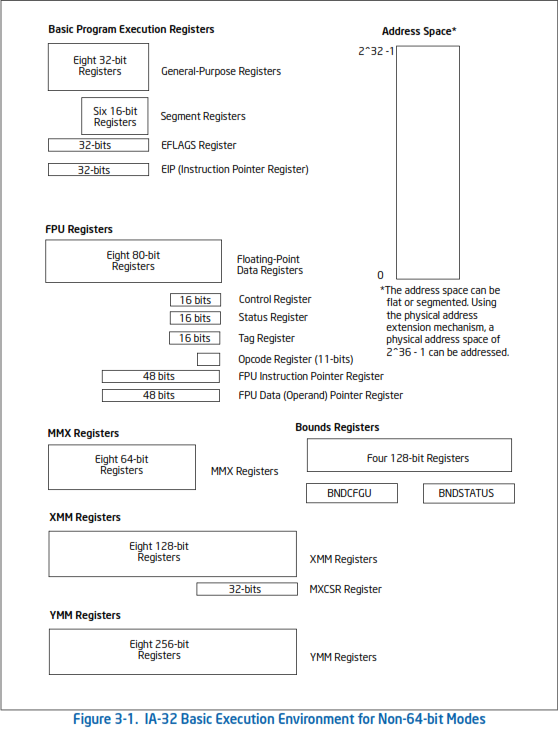
목차 3. 기본 실행 환경(Basic Execution Environment) 3.1. 작동 방식(Modes of Operation) 3.1.1. Intel® 64 아키텍처(Intel® 64 Architecture) 3.2. 기본 실행 환경의 개요(Overview of the Basic Execution Environment) 3.2.1. 64비트 모드 실행 환경(64-Bit Mode Execution Environment) 3.3. 메모리 조직(Memory Organization) 3.3.1. IA-32 메모리 모델(IA-32 Memory Models) 3.3.2. 페이징과 가상 메모리(Paging and Virtual Memory) 3.3.3. 64비트 모드의 메모리 조직(Memory Organiza..