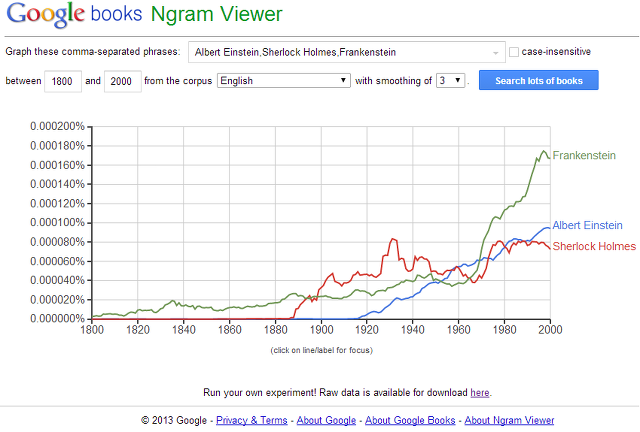
1. 개요 N-gram이란 텍스트, 바이너리 등 전체 문자열을 N 값 만큼 서브스트링(Sub-String)으로 나누어 통계학적으로 사용한 방법을 의미한다. "기계학습"이라는 단어를 2-gram 기준으로 적용하면 "기계", "계학", "학습" 이라는 3가지 하위 문자열들이 각각 빈도수 1로 생성되게 된다. N-gram은 "귀납 학습" 범주에 속하는 학습 방법으로 구체적인 사례를 통해 공통점을 추출하는 형태이다. 이렇게 N-gram은 조각난 문자열을 통해 발생하는 출현 빈도를 암기(학습)하여 사용하는 것이다. 이 기법을 사용하는 대표적인 사례는 구글 북스 엔그램(Google Books N-gram)이 있다. 구글이 모든 책들을 디지털화 시키면서 함께 진행하는 프로젝트로 문화의 전개 방향이라던가, 시대가 보려..
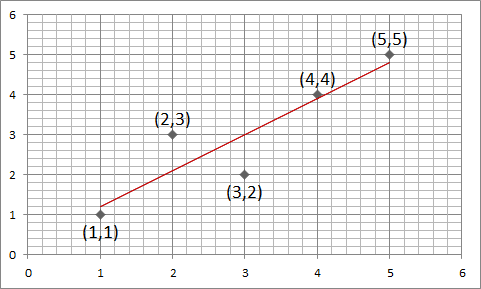
학습 데이터를 이용한 기계 학습과 파라미터 조정은 앞서 언급한 내용대로 어떤 데이터 셋을 가지고 학습을 진행했는가에 따라 파라미터의 값이 바뀌게 된다. 수학적으로 접근하면 학습 데이터에 의해 수식이라는 표현 형식으로 나타내어 프로그램을 운영하게 된다. 대용량의 데이터를 데이터 마이닝을 작업하는데있어 파라미터 조정에 의거한 기계 학습을 진행하는 것은 데이터의 전체적인 추이, 경향 등을 추출하기 위함으로써 통계적인 기법에 의거한다. 통계학에서 학습 데이터가 수치로 주어졌을 때 그 수치를 설명할 수 있는 수식을 "회귀 분석"이라 한다. 회귀 분석의 대표적인 방법으로는 "최소제곱법(Least Squares Method)"가 있다. 1차 방정식으로 표현된 최소제곱법 2차 방정식으로 표현된 최소제곱법 붉은 점은 데..
1970년대 70년대 "귀납 학습"과 함께 진화 연산 방법에 기초한 기계 학습이 제안되었다. 단윈의 진화론 모델화한 기계 학습 방법으로 "유전(자) 알고리즘", "생물 진화 모델", "진화 연산"이라고 불리기도 한다. 일반적으로 생물의 진화에서는 환경과 상호작용하면서 환경에 더 적합한 형태로 진화되어 가는데 적자 생존으로 환경에 잘 적응한 세대가 살아남고 그렇지 못한 세대는 사라지는 형태에 의거하여 적합도 함수에 의해 높게 평가된 형태가 살아남고, 그렇지 못한 형태는 사라지는 것으로 이해할 수 있다. 유전 알고리즘(Genetic Algorithm)은 자연세계의 진화과정에 기초한 계싼 모델로 존 홀랜드(John Holland)에 의해 1975년에 개발된 전역 최적화 기법으로, 최적화 문제를 해결하는 기법 ..
1940년대 기계 학습의 연구의 시작은 "인공신경망(Artificial Neural Network)"이라고 할 수 있다. 생물의 신경조직 움직임을 모델로 하여 정보를 처리하는 구조로, 자극에 해당하는 데이터가 다른 신경으로 전달되면서 어떻게 처리하고 학습해야할지 정해지게 된다. 1960년대 프랑크 로젠블라트(Frank Rosenblatt)에 의해 "다층 신경망(Multilayer Neural Network)"이 제안되었고, 이는 "퍼셉트론(Perceptron)"이라 부르게 된다. 퍼셉트론은 비교적 정확히 기술된, 계산에 의한 최초의 신경망 모델이어서 여러 분야에 커다란 영향을 미치게 되었다. 자극을 받는 세포인 "자극층(입력층, 센서층)"은 데이터를 받는 역할을 하고, 자극에 따른 행동을 결정하는 "응답..
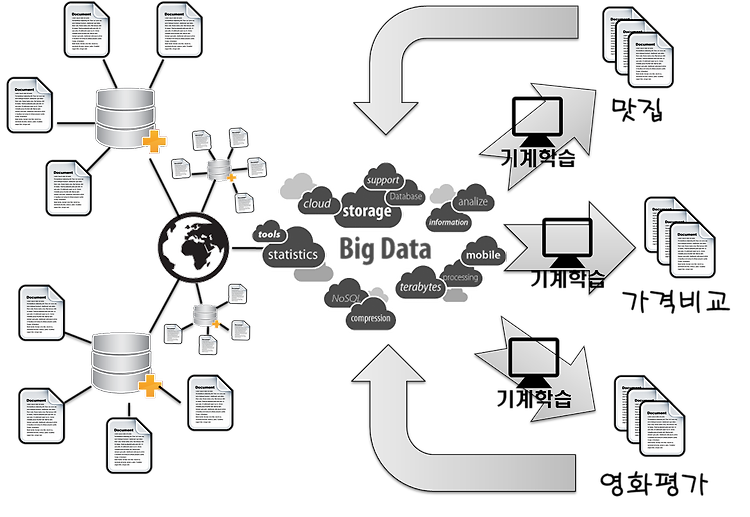
기계학습의 시작은 1950년대 부터 시작되었지만, 그 당시 데이터의 양이 한정되어 있어 학습시킬 데이터가 부족했다. 1959년 아서 사무엘(Arthur Samuel)이 기계 학습을 "컴퓨터에게 배울 수 있는 능력, 즉 코드로 정의하지 않은 동작을 싱행하는 능력에 대한 연구 분야"라고 정의하였다. 그는 1952년 체커를 소재로하여 기계 학습을 하여 스스로 강해질 수 있는 프로그램을 만들었다. 여기서 사용한 기계 학습은 파라미터 조정에 기초한 기계학습 방법이다. - 위키피디아 하지만 현재 인터넷의 발전으로 데이터가 폭발적으로 늘어나 다시 기계학습이 화두가 되고 있다. 특히 빅 데이터의 시대가 도래되면서 방대한 데이터에서 어떤 데이터를 어떻게 효과적으로 사용할 것인가를 해결하기 위해 기계학습을 도입하는 사례가..